Beats 轻量型数据采集器
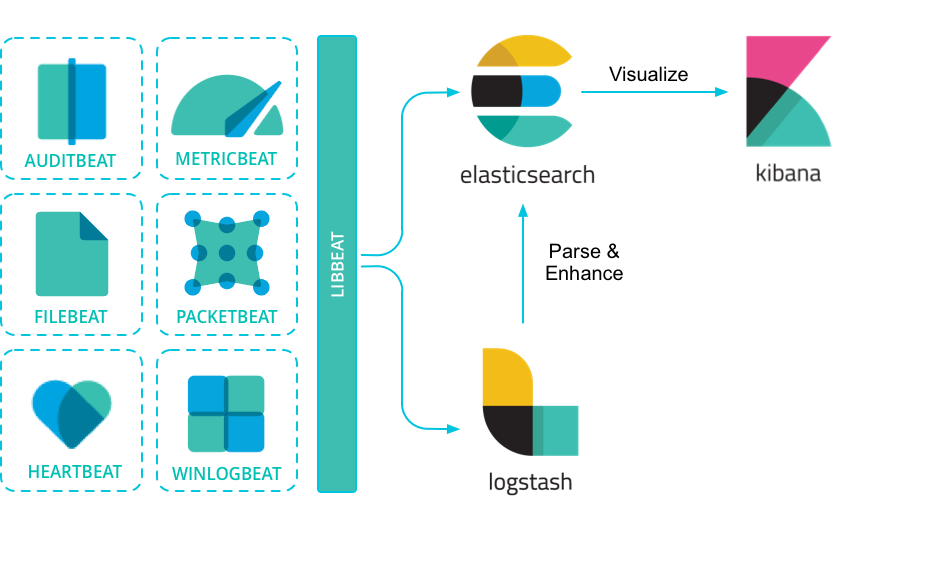
Beats 平台集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
Beats 系列
全品类采集器,搞定所有数据类型。

Beats 可以直接将数据发送到 Elasticsearch 或通过 Logstash,在Kibana 中可视化之前,可以进一步处理和增强数据。
Filebeat
平时我们在查看日志时,使用 tail -f xxx.log 命令来实时查看日志,而当我们要面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,再使用上面的命令来操作几乎是完全不可能的。Filebeat 为我们提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。
Filebeat 内置有多种模块(Apache、Cisco ASA、Microsoft Azure、Nginx、MySQL 等等),可针对常见格式的日志大大简化收集、解析和可视化过程,只需一条命令即可。之所以能实现这一点,是因为它将自动默认路径(因操作系统而异)与 Elasticsearch 采集节点管道的定义和 Kibana 仪表板组合在一起。
Filebeat 工作原理
无论在任何环境中,随时都潜伏着应用程序中断的风险。Filebeat 能够读取并转发日志行,如果出现中断,还会在一切恢复正常后,从中断前停止的位置继续开始。
Filebeat由两个主要组件组成: Prospector(收割者) 和 Harvester(勘探者)。
-
Harvester
- 负责读取单个文件的内容
- 如果文件在读取时被删除或重命名,Filebeat 将继续读取文件
-
Prospector
- Prospector 负责管理 Harvester 并找到所有要读取的文件来源
- 如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个 Harvester。
- Filebeat 目前支持两种 Prospector 类型: log 和 stdin
-
Filebeat 如何保持文件的状态
- Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。
- 该状态用于记住 Harvester 正在读取的最后偏移量,并确保发送所有日志行。 如果输出(例如 Elasticsearch 或 Logstash )无法访问,Filebeat 会跟踪最后发送的行,并在输出再次可用 时继续读取文件。
- 在 Filebeat 运行时,每个 Prospector 内存中也会保存的文件状态信息,当重新启动 Filebeat 时,将使用注册文件的数据来重建文件状态,Filebeat 将每个 Harvester 在从保存的最后偏移量继续读取。
- 文件状态记录在
data/registry文件中。
Filebeat 采集日志到架构

安装并配置
下载安装
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.2-linux-x86_64.tar.gz
# 将下载包解压到 /usr/local 目录下
tar xzvf filebeat-7.6.2-linux-x86_64.tar.gz -C /usr/local
新创建配置文件
监听 stdin 输入,并输出到控制台上
filebeat.inputs:
- type: stdin
enabled: true
output.console:
pretty: true
enable: true
启动执行
cd /usr/local/filebeat-7.6.2-linux-x86_64
./filebeat -e -c filebeat-std.yml
# 参数说明
-e: 输出到标准输出,默认输出到syslog和logs下
-c: 指定配置文件
测试
服务启动完成后,在终端上输入 hello,等待一会儿会在控制台上输出如下图所示信息,message 字段就是我们刚才输入内容

下一步计划
Filebeat 采集日志数据发送到 Elasticsearch
