本篇将 Hive 的优化分成三个部分:
- 第一部分是 SQL 通用语法优化,
- 第二部分是针对 Hive 所具有的数据倾斜的优化,
- 第三部分则介绍一些通用性的 Hive 参数设置优化。
一、语法优化
SQL 的语法优化本质上是如何用更少的计算资源干相同的活,基于此延伸出几条原则,这几条原则又拓展出对应的一些具体方法:
原则1:取更少的数
这条原则特别朴素,只要数据量少了运算的效率自然会提升,但如何能够取更少数的同时不影响结果呢?
1、不要用 select *
这条不多说了,一些宽表少则二三十,多则上百列,而实际绝大多数都是我们不需要的,在 select 时只挑选后续需要用到字段而不是 select *,那么运算时间会成倍减少。
2、谓词下推
谓词下推指:
将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。
简单来说就是把 where 语句尽可能挪到最底层的位置,在最底层就把不需要的数据都过滤掉,然后让真正需要的数据参与运算,而不是留到最后才进行过滤。
根据谓词下推的思想,可对下面的代码进行优化:
select t1.name, t2.age, t2.class, t2.income from t1 join t2 on t1.id = t2.id where t2.age > 18
优化后:
select t1.name, t2.age, t2.class, t2.income from t1
join
(select id, age, class, income from t2 where id > 18) t2
on t1.id = t2.id
3、多用子查询
基于谓词下推的思想,我们还可以做进一步的优化,即多用子查询,上面的代码可进一步优化成如下样子:
select t1.name, t2.age, t2.class, t2.income from
(select id, name from t1) t1
join
(select id, age, class, income from t2 where age > 18) t2
on t1.id = t2.id
采用子查询后,尽管会增加 job 数但提前把数据完成了过滤,还提高了代码的可读性,尤其是当需要关联的表和条件成倍增加后,可读性将会非常重要。
4、子查询的去重
当子查询的表中所需的字段存在重复值,那么对这些字段提前进行去重再进行关联同样会提高运算效率。还是以上面的代码为例:
select t1.name, t2.age, t2.class, t2.income from
(select id, name from t1) t1
join
(select id, age, class, income from t2 where age > 18 group by id, age, class, income) t2
on t1.id = t2.id
至于为什么用 group by 而不是 distinct 去重会在数据倾斜部分进行解释。
5、过滤null值
当关联所用到的字段包含了太多 null 时,需要从业务的角度考虑这些为 null 的数据是否有存在的必要,如果不必要的话尽早过滤掉,避免影响关联的效率。
如果确实需要用到,则可用 rand() 把数据均匀分布在不同的 reduce 上,避免数据倾斜,详细可见第二部分,此处仅列出代码:
select
n.*,
o.name
from
nullidtable n
full join
bigtable o
on nvl(n.id,rand())=o.id
原则2:不排序
SQL 中进行排序是要消耗计算资源的,在 Hive 中这种资源消耗会更加明显。子查询里不要排序这一点就不多说了,子查询中排序是毫无意义的,同时在最后的结果步也尽可能少排序,排序这需求完全可以通过交互查询的UI或把结果数据导出进行替代解决。当然,如果进行查询时没有UI系统,或者不方便把数据导出,或者你就是想即时看到数据的排序情况,就当这条建议不存在就好,但在子查询里排序仍然还是毫无意义的。
原则3:分步
该原则主要目的是把大数据集拆成小数据集来运行。
1、减少在 selec 时用 case when
有时出结果时需要用 case when 进行分类输出,如下面例子
select
dt,
count(distinct case when id=1 then user_id else null end) as id_1_cnt,
count(distinct case when id=2 then user_id else null end) as id_2_cnt
from table_1
where dt between '20200511' and '20200915'
group by dt
但是实测发现 case when 的执行效率很低,当数据量太大的时候甚至会跑不出数,因此上面的代码可优化成如下形式:
select
t1.dt,
t1.id_1_cnt,
t2.id_2_cnt
from
(select
dt,
count(distinct user_id) as id_1_cnt
from table_1
where dt between '20200511' and '20200915' and id=1
group by dt) t1
left join
(select
dt,
count(distinct user_id) as id_2_cnt
from table_1
where dt between '20200511' and '20200915' and id=2
group by dt) t2
on t1.dt=t2.dt
当数据量很大或者 select 时有太多的 case when,采用上面的方式其执行效率会提高 10 倍以上。
2、多用临时表
当需要建的表其逻辑非常复杂时,需要考虑用临时表的方式把中间逻辑分布执行,一来方便阅读、修改和维护,二来减少硬盘的开销(相较于建中间表的方式)。
3、where+union all
当需要根据某字段分类汇总时发现运行速度很慢甚至跑不出结果,那么有可能是因为某一类型的数据样本量过大造成数据倾斜,此时可考虑通过 where 过滤 + union all 合并的方法分步统计和汇总来处理该问题。
优化前:
select
age,
count(distinct id) as id_cnt
from age_table
group by age
优化后:
select
age,
count(distinct id) as id_cnt
from age_table
where age<35
group by age
union all
select
age,
count(distinct id) as id_cnt
from age_table
where age>=35
group by age
SQL 语句的优化方法贵精不贵多,牢记上述原则和方法在日常取数建表写 SQL 时大部分情况下就已经接近最优效率了。
二、数据倾斜
在展开数据倾斜的优化之前,需要先了解 Hive 所采用 MapReduce 的原理
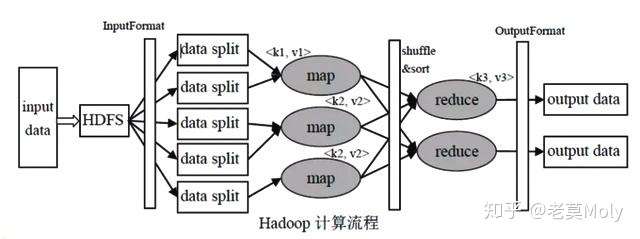
以上图为例,快速过一遍 MapReduce 的工作流程:
1、首先把需要处理的数据文件上传到 HDFS 上,然后这些数据会被分为好多个小的分片,然后每个分片对应一个 map 任务,推荐情况下分片的大小等于 block 块的大小。然后 map 的计算结果会暂存到一个内存缓冲区内,该缓冲区默认为 100M,等缓存的数据达到一个阈值的时候,默认情况下是 80%,然后会在磁盘创建一个文件,开始向文件里边写入数据。
2、map 任务的输入数据的格式是 key-value 对的形式,然后 map 在往内存缓冲区里写入数据的时候会根据 key 进行排序,同样溢写到磁盘的文件里的数据也是排好序的,最后 map 任务结束的时候可能会产生多个数据文件,然后把这些数据文件再根据归并排序合并成一个大的文件。
3、然后每个分片都会经过 map 任务后产生一个排好序的文件,同样文件的格式也是 key-value 对的形式,然后通过对 key 进行 hash 的方式把数据分配到不同的 reduce 里边去,这样对每个分片的数据进行 hash,再把每个分片分配过来的数据进行合并,合并过程中也是不断进行排序的。最后数据经过 reduce 任务的处理就产生了最后的输出。
简单来说,map 阶段负责不同节点上一部分数据的统计工作,reduce 阶段负责汇总聚合的工作。
有时一个 reduce 可以处理多个任务,但一些全局的工作只能让一个 reduce 负责,例如统计总行数、distinct去重等,此时就 reduce 就不能有多个实例并发执行,这就会造成其他 reduce 的任务已经执行完了,而负责全局的 reduce 还没执行完,这就是数据倾斜的本质,因此避免数据倾斜的核心在于均匀分配任务。
1、数据量大的时候用group by
当需要对数据进行去重时,在数据量较大的情况下可以选择用 group by 而不是 distinct,原理如下:
默认情况下,map 阶段同一 key 数据分发给一个 reduce,当一个 key 数据过大时就会发生数据倾斜了。但是并不是所有的聚合操作都只能在 reduce 完成,很多聚合操作也可以先在 map 进行部分聚合,最后在 reduce 端得出最终结果。
开启 Map 端聚合参数设置
(1)是否在 Map 端进行聚合,默认为 true
set hive.map.aggr = true;
(2)在 Map 端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
(3)有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true;
当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map 的输出结果会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
而与之相对应的,distinct 则只会用一个 reduce 来执行,造成数据量过大而让整体任务执行时间过长或无法完成。
但是需要注意的是,用 group by 来去重会额外增加一个子查询,只有当数据量很大的情况或任务执行中出现严重的数据倾斜,group by 去重后 count 才会比 count(distinct) 效率更高。
2、Mapjoin
如果不指定 MapJoin 或者不符合 MapJoin 的条件,那么 Hive 解析器会将 Join 操作转换成 Common Join,即:在 Reduce 阶段完成 join。容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存在 map 端进行 join,避免 reducer 处理。
(1)设置自动选择 Mapjoin
set hive.auto.convert.join = true; 默认为true
(2)大表小表的阈值设置(默认25M以下认为是小表):
set hive.mapjoin.smalltable.filesize=25000000;
数据倾斜的处理在 Hive 优化中是一个大课题,实际场景中所遇到的 Hive 任务执行过长或报错有80%都与数据倾斜有关,后续有机会的话可能专门写一篇针对解决数据倾斜的文章。
三、参数优化
该部分罗列了一些常用的 Hive 参数设置,并逐条做简单介绍
1、set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveFormat;(默认开启)
将多个小文件打包作为一个整体的 inputsplit,减少 map 任务数
2、set hive.merge.mapfiles=true;(默认值为真)
合并 map 端小文件的输出
3、set hive.auto.convert.join=true;
开启 mapjoin
4、set hive.mapjoin.smalltable.filesize=25000000; (默认25M)
设置 mapjoin 的开启阈值
5、set hive.optimize.skewjoin=true;
有数据倾斜的时候进行负载均衡
6、set hive.skewjoin.key=100000;
表示当记录条数超过100000时采用 skewjoin 操作
7、set hive.exec.parallel=true;
多个 join 多个 union all 优化,开启不同 stage 任务并行计算
8、set hive.exec.parallel.thread.number=16;(默认为8)
同一个 SQL 允许最大并行度
9、set hive.map.aggr=true;
group by 数据倾斜优化 设置在 map 端进行聚合
10、set hive.groupby.skewindata=true;
group by 数据倾斜优化
11、set hive.exec.mode.local.auto=true;
开启本地模式
12、set mapred.compress.map.output=true;
开启中间压缩
以上是 Hive 通用属性的设置,下面的参数主要目的是控制 map 和 reduce 的数量,需要依情况而设定:
13、set hive.merge.smallfiles.avgsize=16000000;
平均文件大小,是决定是否执行合并操作的阈值
14、set mapred.min.split.size.per.node=128000000;
低于 128M 就算小文件,数据在一个节点会合并,在多个不同的节点会把数据抓取过来进行合并
15、set mapred.min.split.size.per.rack=64000000;
每个机架处理的最小 split
16、set mapred.max.split.size=256000000;
决定每个 map 处理的最大的文件大小
17、set mapred.min.split.size=10000000;
决定每个 map 处理的最小的文件大小
18、set hive.merge.size.per.task=256000000;(默认值为256000000)
对 map 个数进行设置
19、set mapred.reduce.tasks=10;
设置 reduce 的数量
20、set hive.exec.reducers.bytes.per.reducer=536870912;(512M)
调整每个 reduce 处理数据量的大小
以上关于 map 和 reduce 的参数需要根据实际情况设置,具体的设置逻辑碍于篇幅所限就不展开了,如果有机会的话需要单独列一篇作详细介绍。
除了以上的优化方向外,还可以通过设置 Hive 的文件格式来提高效率,目前优化做得最好的文件格式就是 ORCfile,可以在建表时通过 stored as ORC 来调用。另外,可以根据实际工作需要把一些常用的统计汇总逻辑用中间表的形式存储起来,便于后续查询。
Hive 的优化是一个系统性的工作,本篇仅列一二,但是由于以后是 Spark 以及其他更优秀引擎的天下了,所以如果以后还要对 Hive 进行优化,那大概就是换一个语言吧(不是)。
如果觉得还有帮助的话,你的关注和转发是对我最大的支持,O(∩_∩)O:
