原文链接:https://blog.csdn.net/gaixiaoyang123/article/details/104000982
(一)该如何理解事实表
事实表作为维度建模的另一个核心,是紧贴着业务过程来进行设计和描述的。相对于维度表来说,事实表要大的多,由于承载了具体的业务过程,因而变化也非常大。与维度表不同的是,事实表可以存储维度属性信息。事实表通常有三种分类:事务事实表、快照事实表与其他类型事实表,其中快照事实表又分为周期快照事实表与累积快照事实表。
因为历史数据的关系,事实表通常比较需要比较多的例子来辅助说明,因而会难以理解。本文将尽可能用简单的方式阐述事实表的设计方式,毕竟业务场景不同,所面临的问题也是截然不同的。
(二)事实表设计原则
不论通过何种方式、设计怎样的事实表,都需要遵循一定的原则。原则不仅是软件开发过程所需要遵守的潜在规定,同样也是架构、数据仓库需要遵守的约束原则。
事实表的设计原则有如下几种:
1. 包含所有与业务场景相关的事实:事实表设计的初衷,即是为了描述和统计业务的相关过程,因而将所有业务信息包含进来,非常有必要;
2. 规避与业务场景无关的事实:本条与上条相对应,但需要强调一下,很多事实表习惯性的加入了很多的统计指标,以追求大而全,这样做是不对的,不同主题域的数据,应尽量避免混在一起统计,非常容易出现join的时候关联不上或者多了几条的情况;
3. 分解部分不可加性事实为可加组件:例如点击率=点击数量/展现数量,在表中应该分别保存点击数量与展现数量;
4. 确定最小粒度:粒度决定了事实表所统计的指标层次,同时也是维度表扩展的必要属性,因此有必要在设计表之前,先确定表的最细粒度,后期扩展便灵活了很多;
5. 同一事实表不能有多种不同粒度的事实:这一条比较好理解,不同粒度的统计项在一张表里,容易造成重复计算的问题;
6. 保持单位一致:同一张事实表中相同事实的单位,应该保持一致,例如计费表中有充值金额、消费金额和返还金额,需要统一设定为元或者分;
7. 空值处理:null值在Hive等环境中,对SQL的查询及过滤环境均不生效,需要很复杂的逻辑来处理空值,因而遇到空值时,建议用0或者随机数来填充;
8. 适当通过退化维度提高事实表的通用性:在大数据环境下,如果每一次计算都需要维度表与事实表相关联,计算和使用的复杂性都会提高不少,因而可以根据实际情况,适当退化部分维度到事实表中,可以减少关联操作,便于下游平台使用。
(三)事实表设计方法
Kimball在书中提到了维度模型的四步设计方法:选择业务过程、声明粒度、确定维度、确定事实。在阿里系中工作时间长了,各部门与数据团队都倾向于统一模型的设计方法,对于后期向ODPS数据迁移等工作有很大的帮助。因而这里采用了阿里系的改进版方法,来阐述事务事实表的设计方法。具体有如下几步:
1. 根据业务过程确定事实表:接到业务需求后,需要分析业务的整个过程与生命周期,拆解出其中的关键步骤,从而建立事务事实表。例如广告的流程有如下几步:创建用户、创建投放计划、投放不同渠道、统计点展销等指标,因而事实表的创建就围绕着用户、计划、渠道和指标四个角度展开。
2. 声明粒度:粒度是事实表中非常重要的一步,出现了问题大概率就会出现重复计算导致指标错误的情况。因此需要根据业务的过程,选择最细级别的原子力度,以保证后期上卷统计有更好的灵活性。例如产品要求统计到订单粒度,但实际业务过程最细粒度是子订单,那么在创建事实表的过程中中应该围绕子订单来进行统计。
3. 确定维度:声明了最细粒度,也就意味着确定了主键,其相对应的维度属性也就可以确定。
4. 确定事实:事实应该选择与业务过程相关的所有选项,并且粒度与声明的最细粒度一致。
5. 冗余维度:这一步是针对大数据环境下维度建模的特别步骤,主要为了统计和下游使用的便捷性,适当冗余部分维度,虽然破坏了星型模型的规则,但提高了灵活性。
(四)事务事实表
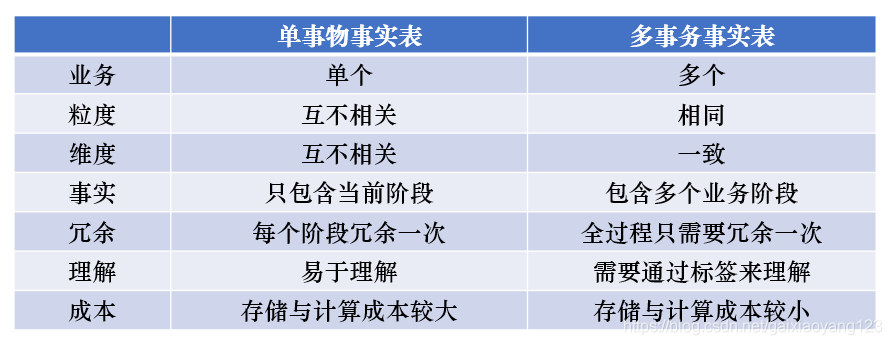
事实表通常有三种分类:事务事实表、快照事实表与其他类型事实表,其中最常涉及到的是事务事实表,设计过程上文已经提及,就不再赘述。但事务事实表的设计通常是面向整个业务过程的,而业务过程会有不同阶段的任务,因而实际上针对每个阶段单独做统计、还是将所有阶段放在一起统计,就产生了单事物事实表与多事物事实表的区分。
单事物事实表,即针对每一阶段的业务过程设计一个事实表,优点是构建逻辑十分清楚,缺点是其复杂程度与阶段的设定密切相关。
多事务事实表,指将不同阶段的事实放到同一张事实表中,即一张事实表包含了多个不同的业务过程。
两种设计的优劣势比较如下表所示:
(五)快照事实表
采用事务事实表基本上能够将一个完整的业务过程描述清楚,但针对一些周期性倾向的数据,例如交易金额的历史变化、商品库存的累积情况,事物事实表就不太容易描述清楚了,需要通过快照事实表的形式,针对不同周期内的指标情况,进行分类的描述。
快照事实表分为两种:周期快照事实表与累积快照事实表,以下分别阐述。
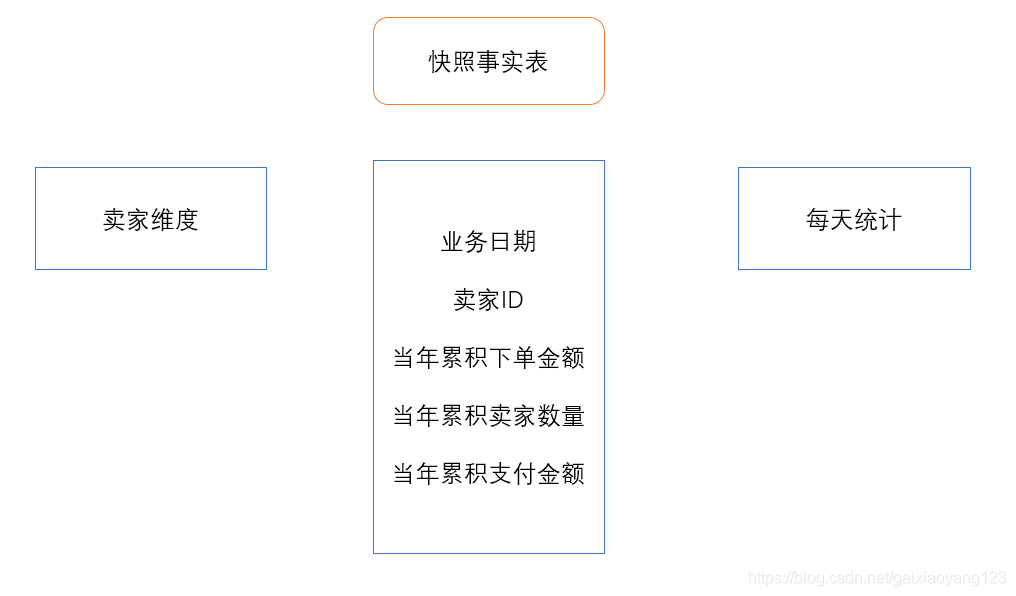
周期快照事实表,通过在确定的时间间隔内,对指标项的情况进行统计,从而得到周期性的度量值。例如应用淘宝系中交易结束后的评价情况、买家累积支付金额、卖家星级变化情况等场景。仍以淘宝系例子来说明,如下快照事实表就记录了卖家的累积交易情况:
累积快照事实表,“累积”的概念与“周期”对应,针对不确定的时间间隔内,对指标项的情况进行统计。例如从支付到收货的周期不定,收货到评价的周期不定等等。因而统计的方式需要每日进行更新,采集最新变化的指标信息。仍以淘宝系例子来说明,例子如下:

(六)其他类型事实表
其他类型事实表主要包括了无事实的事实表、聚集型事实表,分别阐述如下:
1. 无事实的事实表,虽然事实表用来度量业务过程,但可能其并不包含事实或者度量,例如最常见的是日志类事实表,用户的浏览访问记录,会记录在表中,但展现次数及点击次数却不会在该表中统计;另一种是条件、范围或资格类的业务过程,例如产品促销范围等,同样不会有统计信息。
2. 聚集型事实表,该表还有另外一个名字“中间层”,也叫“公共汇总层”,通常将最频繁使用的公共数据沉淀到一张表中,供下游使用。其设计的基本原则有三个:一致性、避免单一表设计及聚集粒度可不同。设计步骤同样是三步:确定聚集维度、确定一致性上钻及确定聚集事实。
如果觉得还有帮助的话,你的关注和转发是对我最大的支持,O(∩_∩)O:
