背景
基础软件安装
- JDK 1.7(之前已经安装过)
- scala-2.11.4
- spark-1.6.0-bin-hadoop2.6
- 集群ssh免密登录配置(之前已经安装过)
服务器分布及相关说明
由于目前只有3台虚拟机,所以分配如下:
| 服务器角色/服务器 | Master(192.168.111.238) | Slave1(192.168.111.239) | Slave2(192.168.111.240) |
|---|---|---|---|
| Master | Y | N | N |
| Worker | N | Y | Y |
安装步骤
以下是在Master机器上操作
安装scala
- 将scala-2.11.4.tgz上传到/usr/local目录下,即 /usr/local/scala-2.11.4.tgz
- 解压 tar -xzvf scala-2.11.4.tgz
- 修改/etc/profile,配置环境变量
export SCALA_HOME=/usr/local/scala-2.11.4和export PATH=$PATH:$SCALA_HOME/bin,然后运行source /etc/profile使环境变量生效。 - 在终端上输入scala进行测试。
安装Spark
- 将spark-1.6.0-bin-hadoop2.6.tgz上传到/usr/local,并解压
tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz得到/usr/local/spark-1.6.0-bin-hadoop2.6 - 修改/etc/profile,配置环境变量
export SPARK_HOME=/usr/local/spark-1.6.0-bin-hadoop2.6和export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin,然后运行source /etc/profile使环境变量生效。 - 配置
spark-env.sh,进入Spark安装目录下的conf目录,拷贝spark-env.sh.template到spark-env.sh。 编辑spark-env.sh,添加以下配置信息:
export SCALA_HOME=/usr/local/scala-2.11.4
export JAVA_HOME=/usr/local/java
export SPARK_MASTER_IP=192.168.111.238
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.1/etc/> hadoop
==========说明===========
JAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;(由于是虚拟机,内存不足)
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录。
- 将 slaves.template 拷贝到 slaves, 编辑其内容为:
slave1
slave2
将Master机器上的上述配置拷贝到slave1和slave2
启动Spark集群
首先确定Hadoop集群启动,否则启动Hadoop集群
- 通过jps命令查看进程
启动Spark集群Master节点
- 执行
./sbin/start-master.sh,可以看到 master 上多了一个新进程 Master
启动Spark集群Slave节点
- 执行
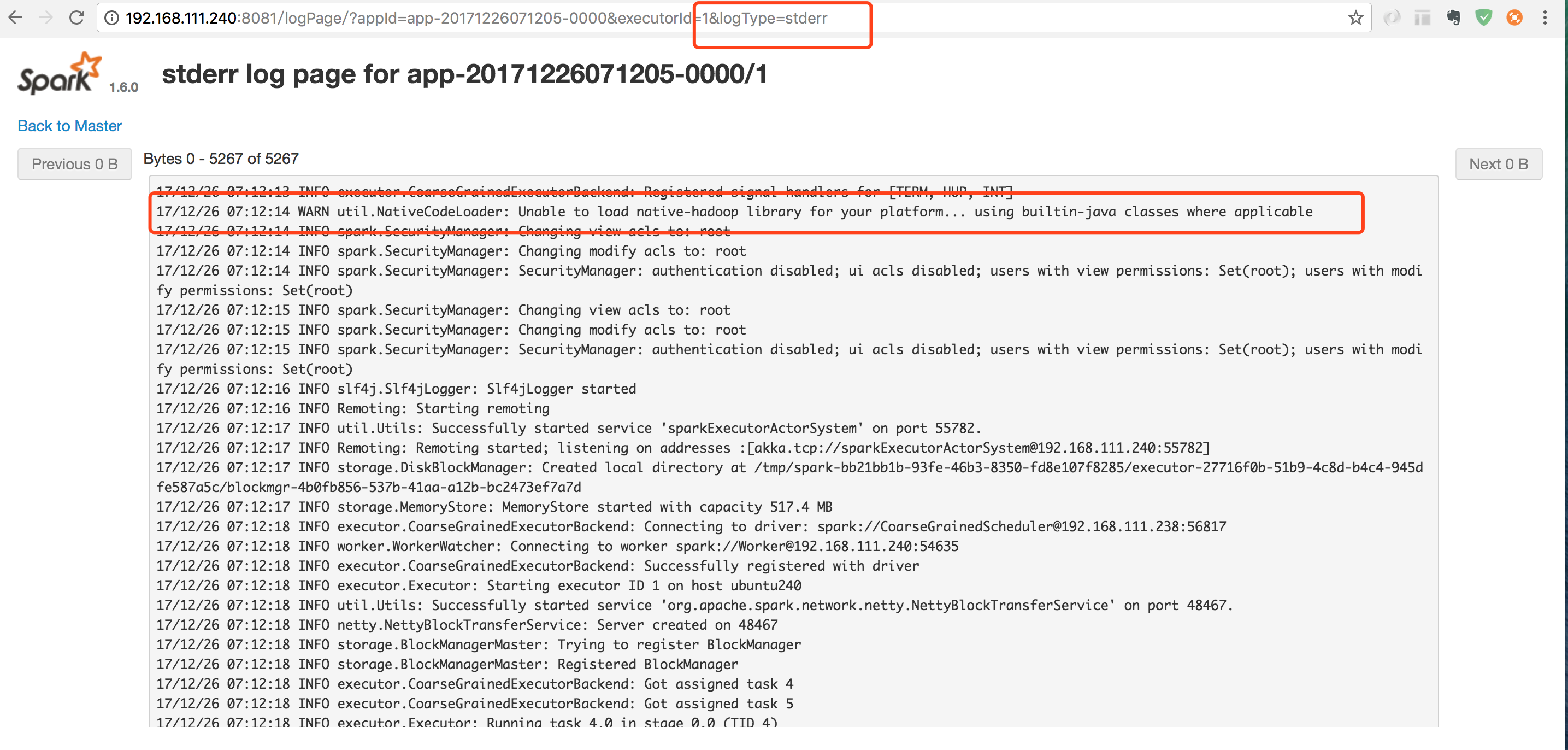
./sbin/start-slaves.sh,日志出现错误


- 查看日志详情,如下图:
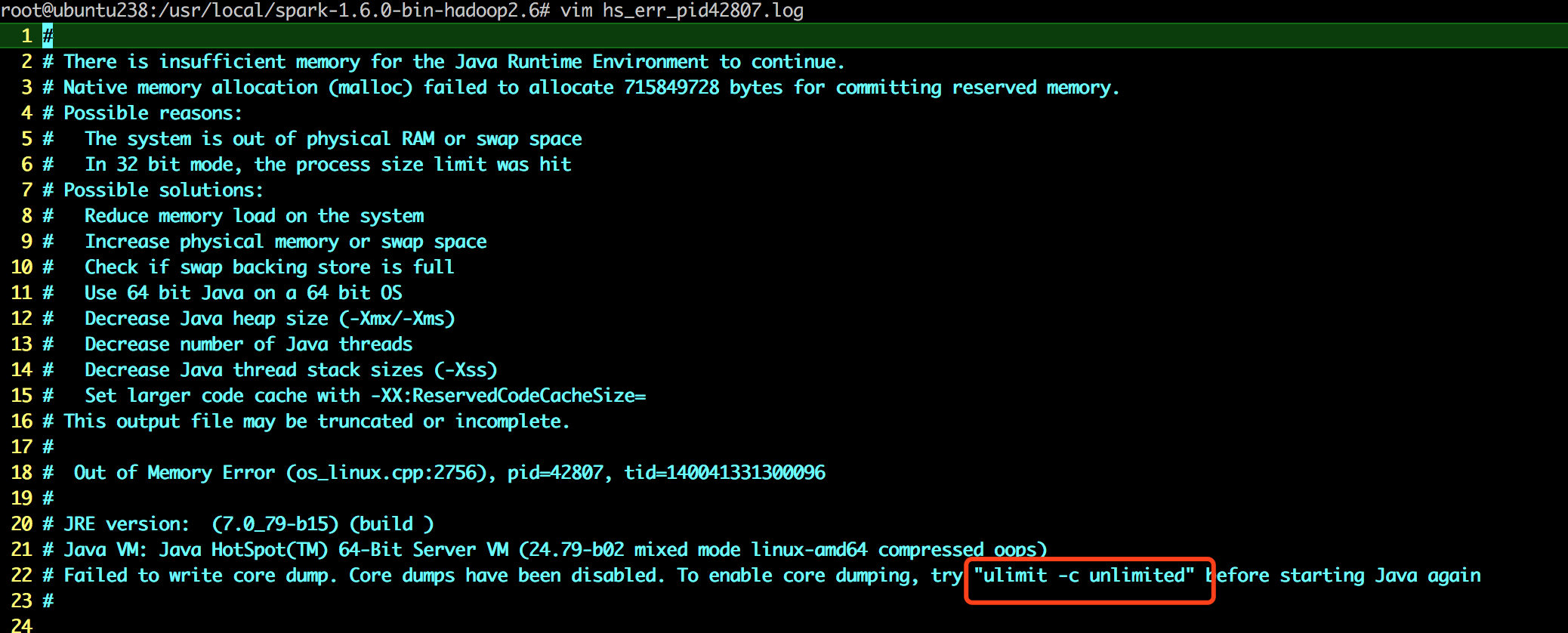
- 执行上图中红框的命令,然后再执行
./sbin/start-slaves.sh,无异常,并用可以看到 slave1 和 slave2 上多了一个新进程 Worker
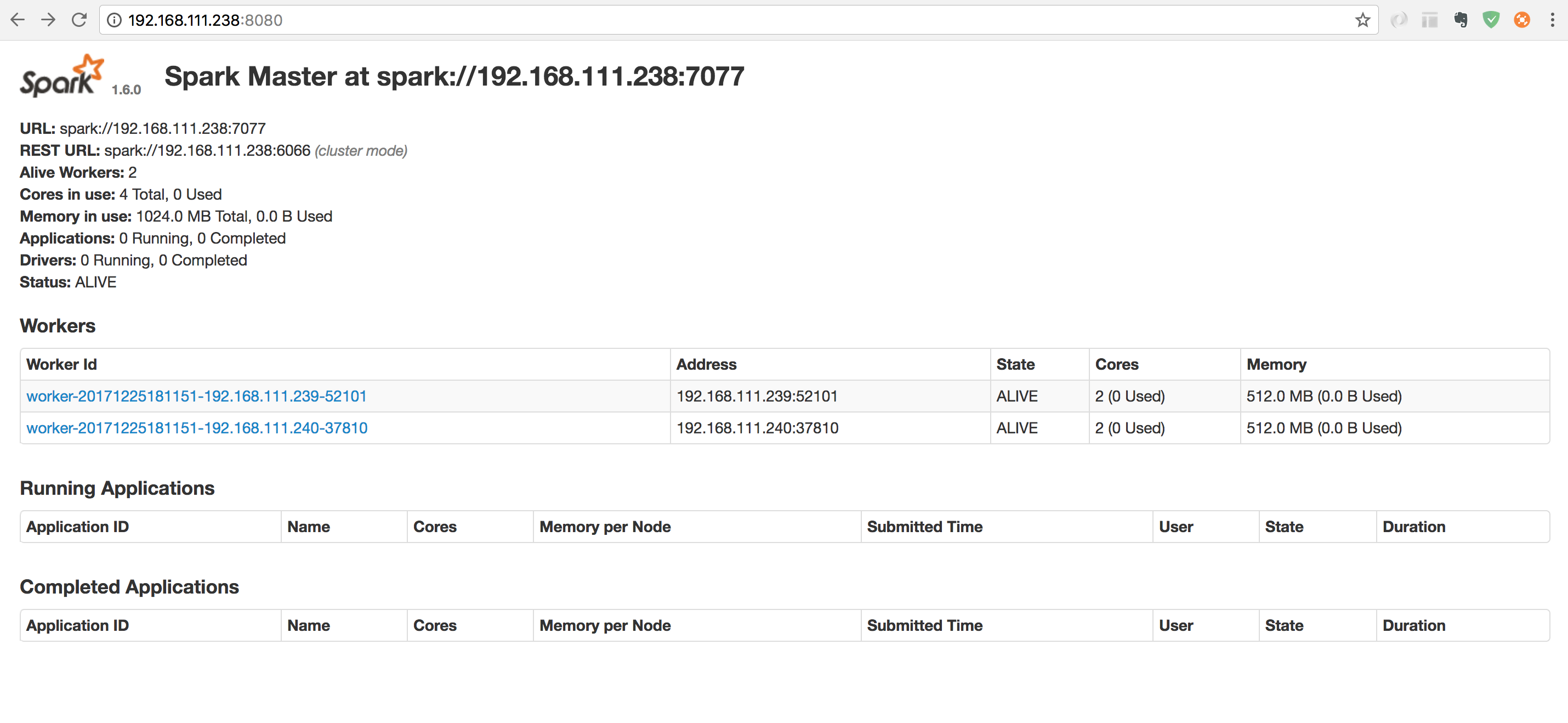
- 浏览器查看 Spark 集群信息
- 使用 spark-shell
./bin/spark-shell

- 修改
cp spark-defaults.conf.template spark-defaults.conf增加spark.driver.memory 1g - 再次执行
./bin/spark-shell启动成功

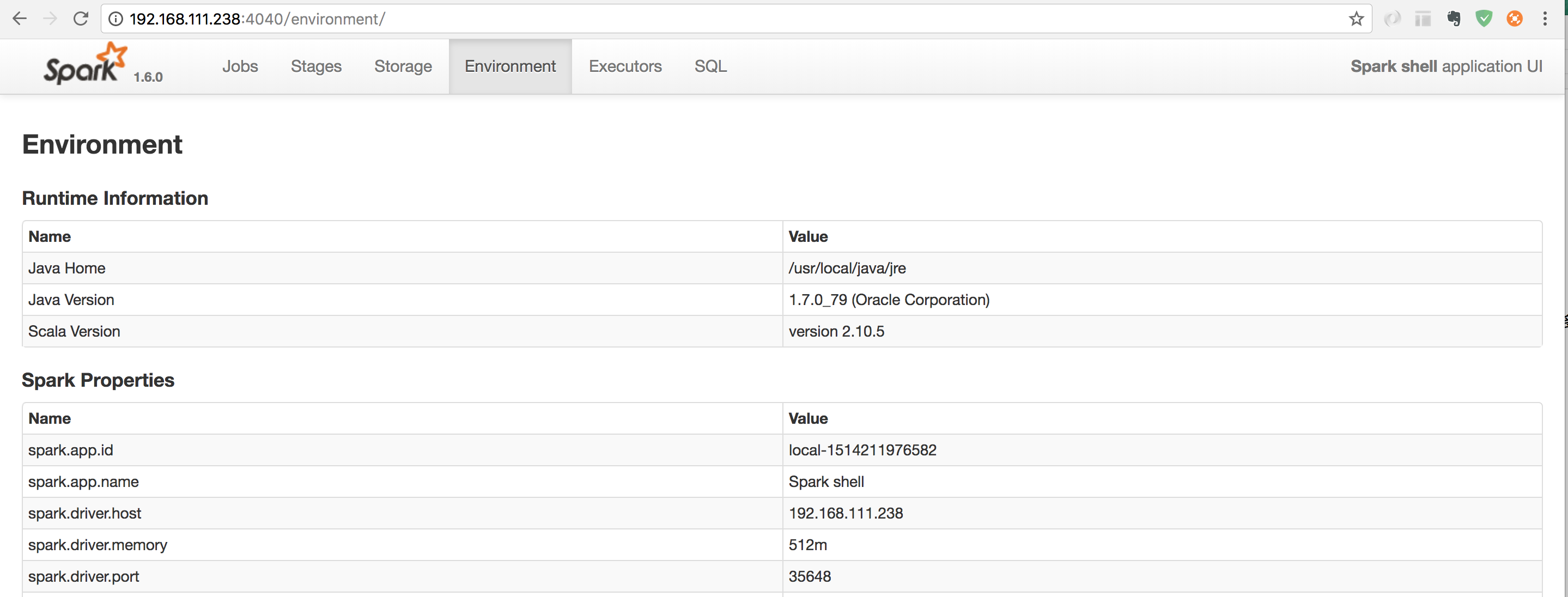
- 浏览器访问 SparkUI
停止Spark集群
- 停止 Master 节点,运行
./sbin/stop-master.sh来停止 Master 节点。使用 jps 命令查看当前 java 进程。发现Master进程已经停止。 - 停止 Worker 节点,在Master机器上运行
./sbin/stop-slaves.sh可以停止所有的 Worker 节点。使用 jps 命令查看 slave1、slave2 上的进程信息,Worker 进程均已停止。
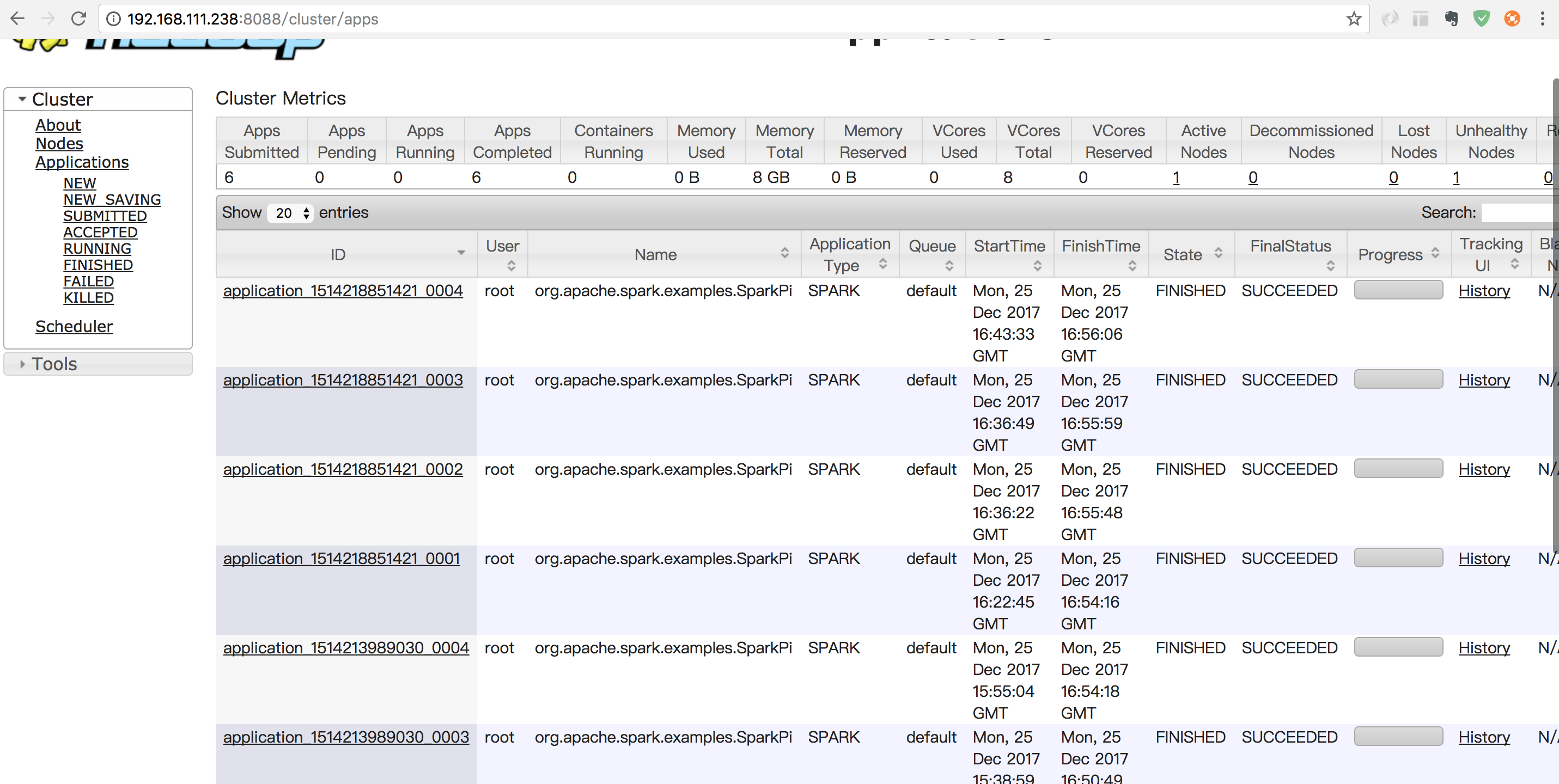
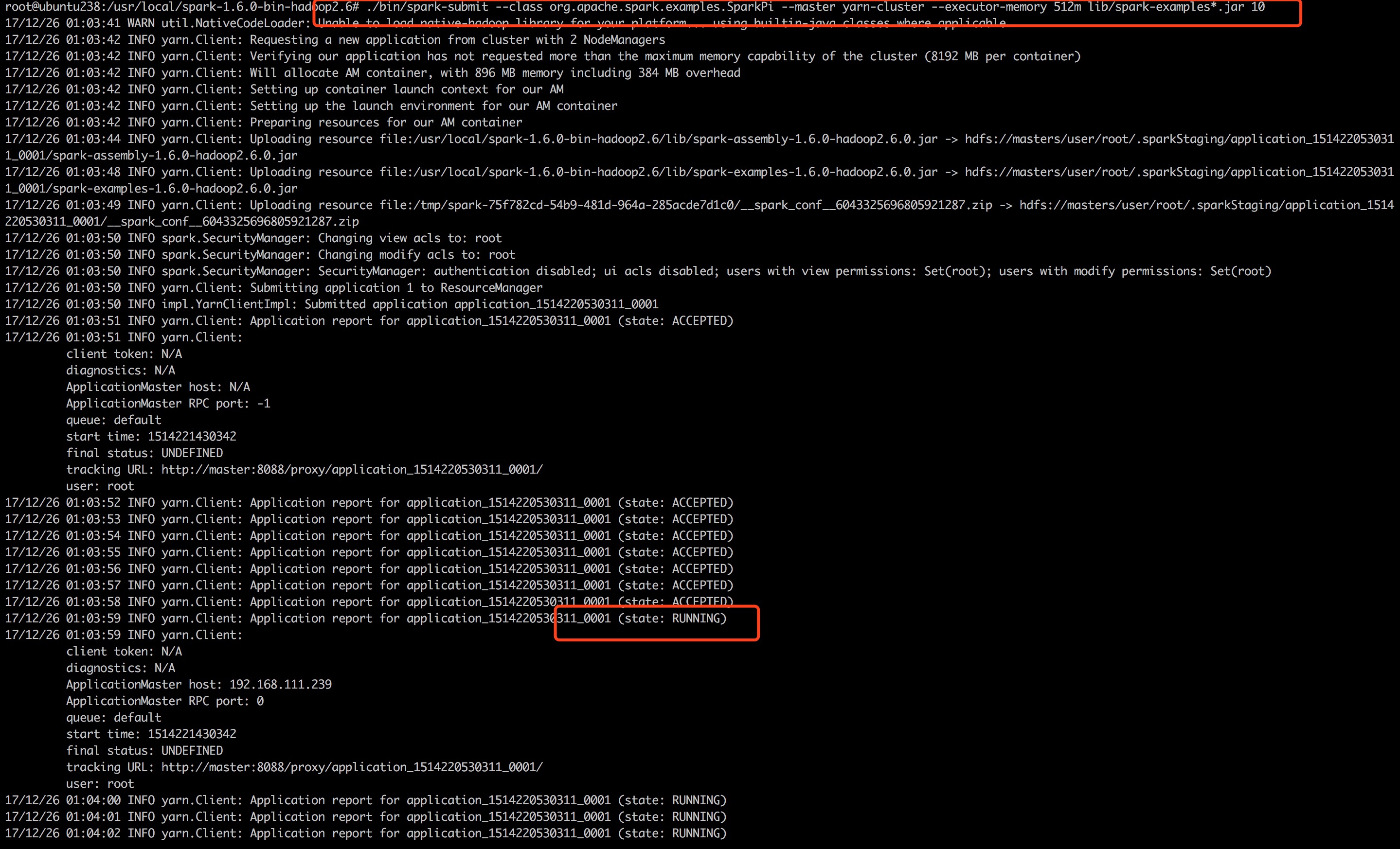
集群测试Spark on Yarn
- 使用系统自带的例子进行集群测试,命令如下:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples*.jar 10
- 命令运行后,不停的输出
17/12/25 18:28:18 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED),如下:
root@ubuntu238:/usr/local/spark-1.6.0-bin-hadoop2.6# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples*.jar 1
17/12/25 18:27:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/25 18:28:00 INFO yarn.Client: Requesting a new application from cluster with 0 NodeManagers
17/12/25 18:28:00 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
17/12/25 18:28:00 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
17/12/25 18:28:00 INFO yarn.Client: Setting up container launch context for our AM
17/12/25 18:28:00 INFO yarn.Client: Setting up the launch environment for our AM container
17/12/25 18:28:00 INFO yarn.Client: Preparing resources for our AM container
17/12/25 18:28:01 INFO yarn.Client: Uploading resource file:/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-assembly-1.6.0-hadoop2.6.0.jar -> hdfs://masters/user/root/.sparkStaging/application_1514124550525_0003/spark-assembly-1.6.0-hadoop2.6.0.jar
17/12/25 18:28:05 INFO yarn.Client: Uploading resource file:/usr/local/spark-1.6.0-bin-hadoop2.6/lib/spark-examples-1.6.0-hadoop2.6.0.jar -> hdfs://masters/user/root/.sparkStaging/application_1514124550525_0003/spark-examples-1.6.0-hadoop2.6.0.jar
17/12/25 18:28:08 INFO yarn.Client: Uploading resource file:/tmp/spark-8cdc6351-f664-4fb9-bcb8-02b24a92d755/__spark_conf__3249902934392270262.zip -> hdfs://masters/user/root/.sparkStaging/application_1514124550525_0003/__spark_conf__3249902934392270262.zip
17/12/25 18:28:08 INFO spark.SecurityManager: Changing view acls to: root
17/12/25 18:28:08 INFO spark.SecurityManager: Changing modify acls to: root
17/12/25 18:28:08 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
17/12/25 18:28:08 INFO yarn.Client: Submitting application 3 to ResourceManager
17/12/25 18:28:08 INFO impl.YarnClientImpl: Submitted application application_1514124550525_0003
17/12/25 18:28:09 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:09 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1514197688778
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1514124550525_0003/
user: root
17/12/25 18:28:10 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:11 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:12 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:13 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:14 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:15 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:16 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:17 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
17/12/25 18:28:18 INFO yarn.Client: Application report for application_1514124550525_0003 (state: ACCEPTED)
从这句17/12/25 18:28:00 INFO yarn.Client: Requesting a new application from cluster with 0 NodeManagers 得知是从集群中没有获得NodeManagers(异常信息这么不明显!!),检查Hadoop集群是否启动正常。发现进程中没有 NodeManager ,原因是,在启动的时候,提示没有JAVA_HOME(JAVA_HOME is not set and could not be found),解决方案
修改/etc/hadoop/hadoop-env.sh中设JAVA_HOME。
应当使用绝对路径。
export JAVA_HOME=$JAVA_HOME //默认:错误
export JAVA_HOME=/usr/local/java //改为自己的java安装目录
然后重启Hadoop进程
./sbin/stop-all.sh
./sbin/start-all.sh
- 再次提交任务,能正常执行。
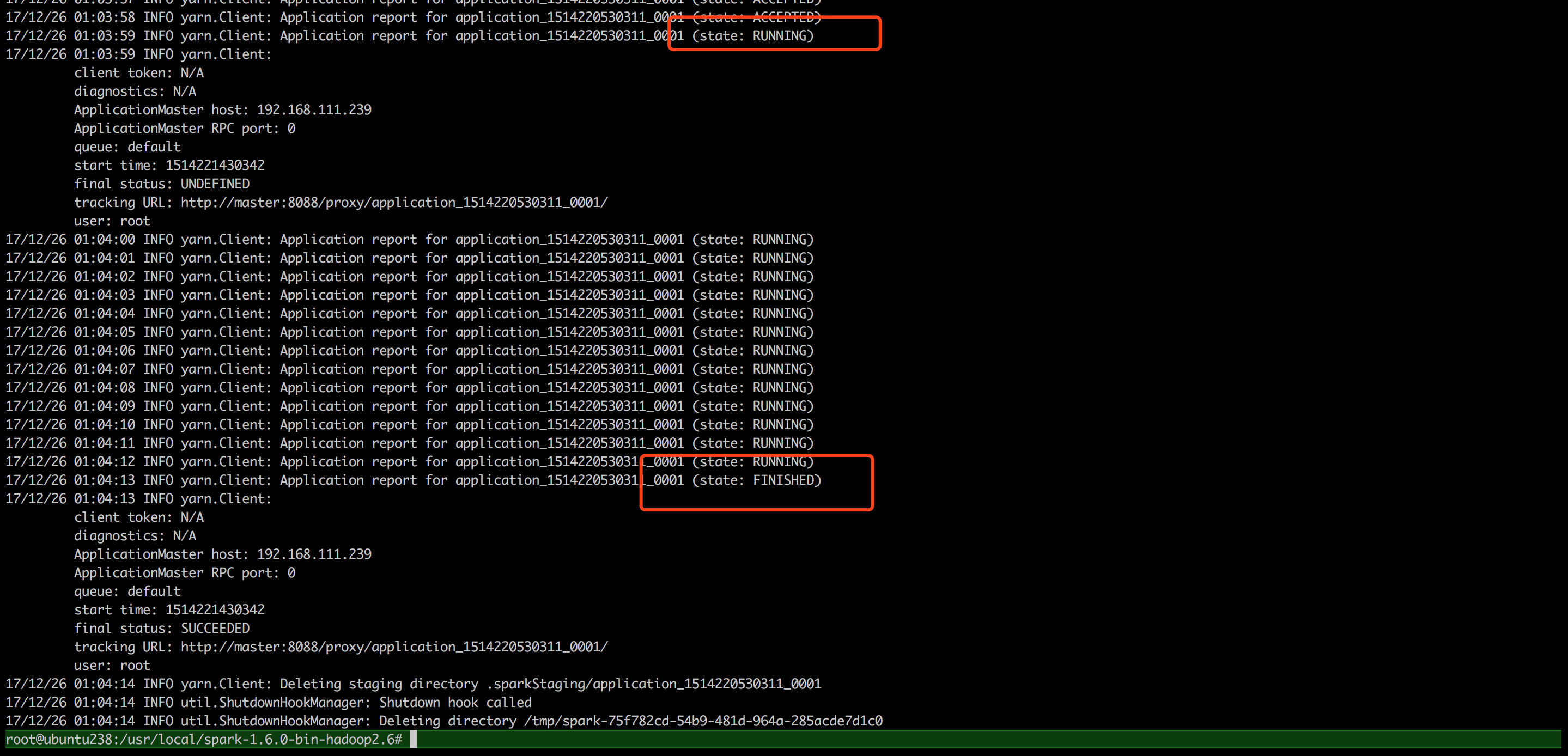
集群测试Spark Standalone
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.111.238:7077 lib/spark-examples*.jar 10
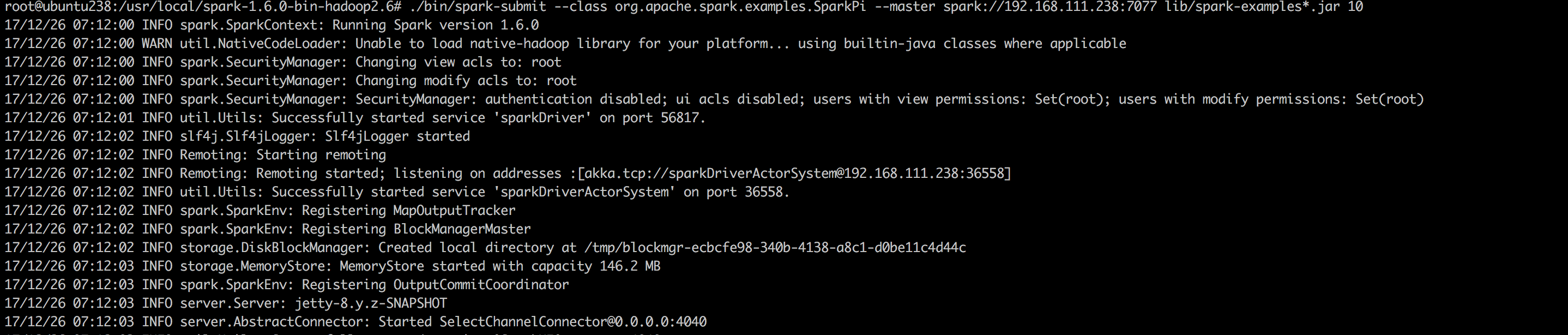
输出了结果

仔细看日志,提示17/12/26 07:12:00 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- 然后看 web ui
http://192.168.111.238:8080/
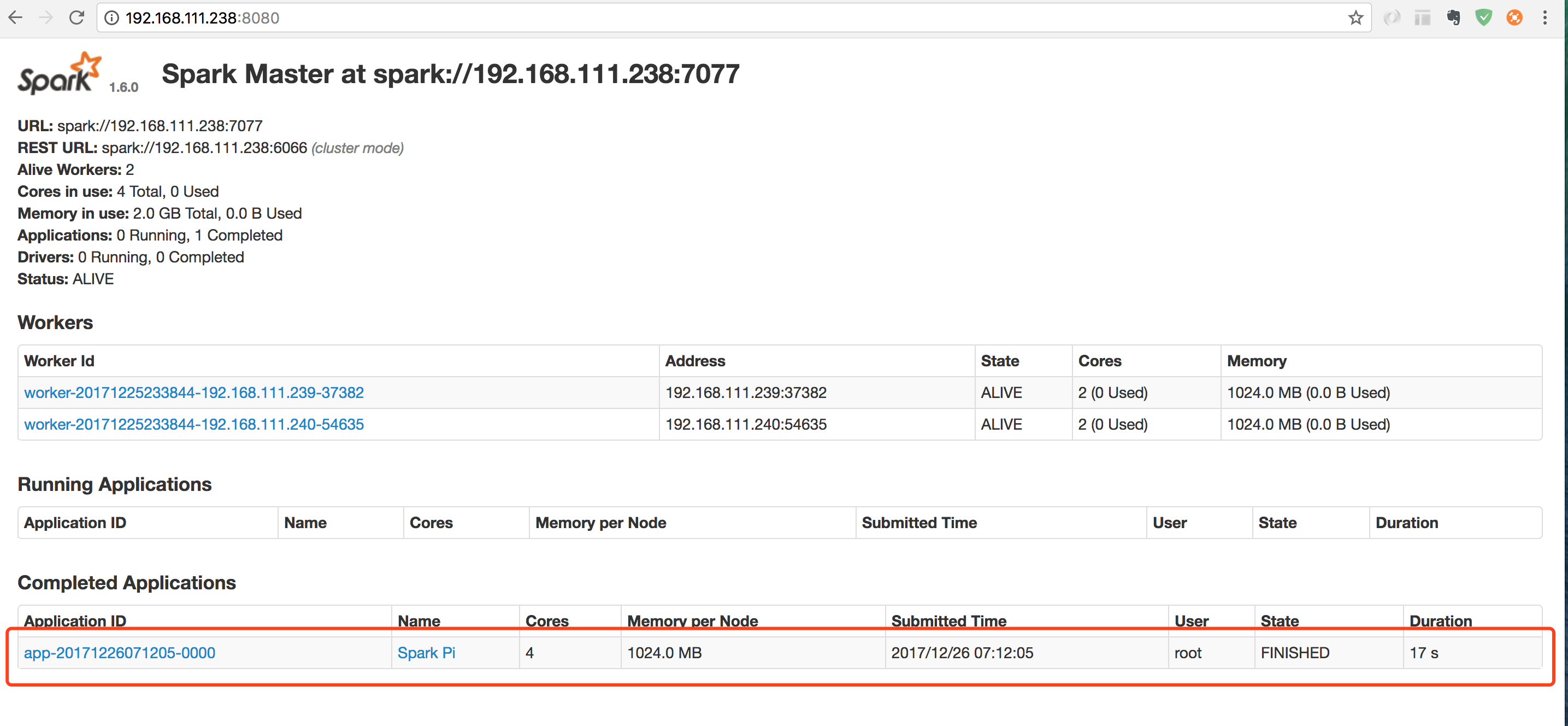
- 点任务名称进去看一下,查看日志
Logs发现stdout 是空的,stderr是有的日志的,说明运行还是出错了