Hadoop2.0新特性
- NameNode HA
- NameNode Federation
- HDFS快照
- HDFS缓存
- HDFS ACL
NameNode HA
背景
- Hadoop 1.0中NameNode在整个HDFS中只有一个,存在单点故障风险,一旦NameNode挂掉,整个集群无法使用
- 通过HDFS的高可用性将通过在同一个集群中运行两个NameNode (active NameNode & standby NameNode )来解决单点故障风险
- 在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态
- Active NN对外提供服务,负责集群中所有客户端的操作
- Standby NN则不对外提供服务,主要用于备用,它主要维持足够的状态,以便能够在它失败时快速进行切换
架构
-
一个典型的HA集群,NameNode会被配置在两台独立的机器上,在任何时间上,一个NameNode处于活动状态,而另一个NameNode处于备份状态,活动状态的NameNode会响应集群中所有的客户端,备份状态的NameNode只是作为一个副本,保证在必要的时候提供一个快速的转移。
-
为了让Standby Node与Active Node保持同步,这两个Node都与一组称为JNS的互相独立的进程保持通信(Journal Nodes)。当Active Node上更新了namespace,它将记录修改日志发送给JNS。Standby Node将会从JNS中读取这些变化,并持续关注它们对日志的变更。Standby Node将日志变更应用在自己的namespace中,当failover发生时,Standby Node将会在提升自己为Active之前,确保能够从JNS中读取所有的信息,即在failover发生之前Standy持有的namespace应该与Active保持完全同步。
-
为了支持快速failover,Standby Node持有集群中Data Blocks的最新位置是非常必要的。为了达到这一目的,DataNodes上需要同时配置这两个Namenode的地址,同时和它们都建立心跳链接,并把block位置发送给它们。
-
任何时刻,只有一个Active NameNode,否则将会导致集群操作的混乱,两个Active NameNode将会分别有两种不同的数据状态,可能会导致数据丢失,或者状态异常,这种情况通常称为“split-brain”(脑裂,三节点通讯阻断,即集群中不同的Data Nodes却看到了两个Active NameNodes)。对于JNS而言,任何时候只允许一个NameNode作为writer;在failover期间,原来的Standby Node将会接管Active的所有职能,并负责向JNS写入日志记录,这就阻止了其他NameNode基于处于Active状态的问题。
-
总结:基于QJM(在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力)的Hadoop HA方案如下图所示,其处理流程为:集群启动后一个NameNode处于Active状态,并对外提供服务,处理客户端和DataNode的请求,并把editlog写到本地和share editlog(QJM)中。另外一个NameNode处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与Active节点的状态同步。为了实现Standby在Active挂掉后迅速提供服务,需要DataNode同时向两个NameNode汇报,使得Stadnby保存block to DataNode信息,因为NameNode启动中最费时的工作是处理所有DataNode的blockreport。为了实现热备,增加FailoverController和Zookeeper,FailoverController与Zookeeper通信,通过Zookeeper选举机制,FailoverController通过RPC让NameNode转换为Active或Standby。
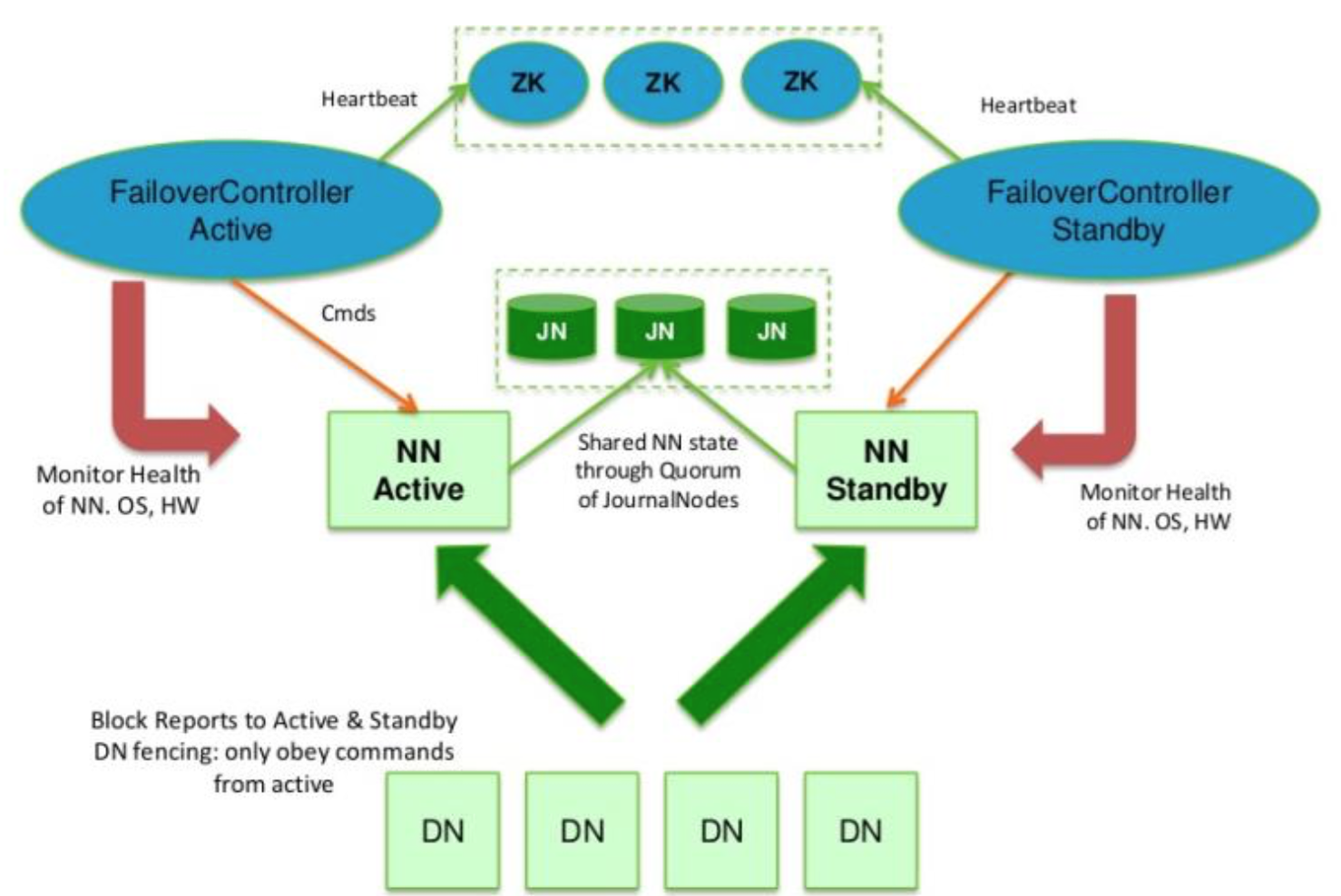
Hadoop HA 要素
-
NameNode机器:两台配置对等的物理机器,它们分别运行Active和Standby Node。
-
JouralNode机器:运行JouralNodes的机器。JouralNode守护进程相当的轻量级,可以和Hadoop的其他进程部署在一起,比如NameNode、DataNode、ResourceManager等,至少需要3个且为奇数,如果你运行了N个JNS,那么它可以允许(N-1)/2个JNS进程失效并且不影响工作。
-
在HA集群中,Standby NameNode还会对namespace进行checkpoint操作(继承Backup Namenode的特性),因此不需要在HA集群中运行SecondaryNameNode、CheckpointNode或者BackupNode。事实上,运行这 些守护进程是错误的
自动故障转移
-
HDFS的自动故障转移主要由Zookeeper和ZKFC两个组件组成。
-
Zookeeper集群作用主要有:一是故障监控。每个NameNode将会和Zookeeper建立一个持久session,如果NameNode失效,那么此session将会过期失效,此后Zookeeper将会通知另一个Namenode,然后触发Failover;二是NameNode选举。ZooKeeper提供了简单的机制来实现Acitve Node选举,如果当前Active失效,Standby将会获取一个特定的排他锁,那么获取锁的Node接下来将会成为Active。
-
ZKFC是一个Zookeeper的客户端,它主要用来监测和管理NameNodes的状态,每个NameNode机器上都会运行一个ZKFC程序,它的职责主要有:一是健康监控。ZKFC间歇性的ping NameNode,得到NameNode返回状态,如果NameNode失效或者不健康,那么ZKFS将会标记其为不健康;二是Zookeeper会话管理。当本地NaneNode运行良好时,ZKFC将会持有一个Zookeeper session,如果本地NameNode为Active,它同时也持有一个“排他锁”znode,如果session过期,那么次lock所对应的znode也将被删除;三是选举。当集群中其中一个NameNode宕机,Zookeeper会自动将另一个激活。
NameNode Federation
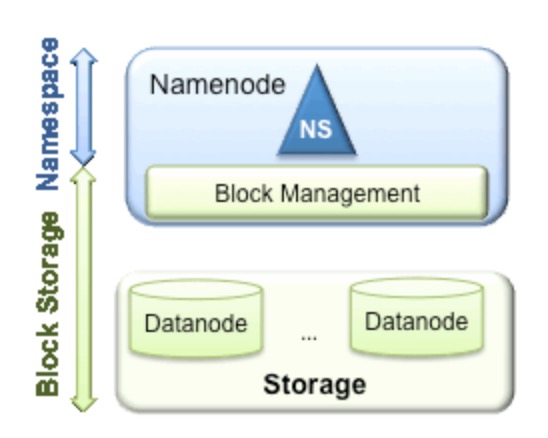
- 在Hadoop 1.0中,HDFS的单NameNode设计带来诸多问题,包括单点故障、内存受限制约集群扩展性和缺乏隔离机制(不同业务使用同一个NameNode导致业务相互影响)等,为了解决这些问题,Hadoop 2.0引入了基于共享存储的HA解决方案和HDFS Federation。
-
HDFS Federation是指HDFS集群可同时存在多个NameNode,这些NameNode分别管理一部分数据,且共享所有DataNode的存储资源。这种设计可解决单NameNode存在的以下几个问题:
(1)HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再像1.0中那样由于内存的限制制约文件存储数目。
(2)性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
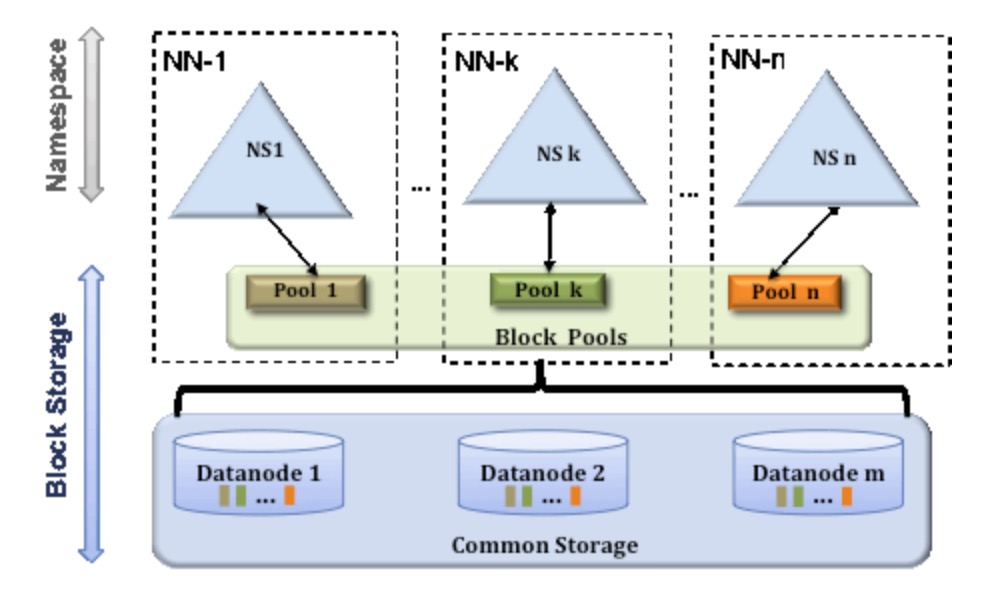
- 但是,HDFS Federation并不能解决单点故障问题,每个NameNode都存在单点故障问题,需要为每个NameNode部署一个backup NameNode以应对NameNode挂掉对业务产生的影响。
HDFS快照
-
快照SNAPSHOT是HDFS文件系统的只读的基于某时间点的拷贝,可以针对某个目录,或者整个文件系统做快照。快照比较常见的应用场景是数据备份,以防一些用户错误或灾难恢复。
(1)快照可以即时创建,耗时仅为O(1)。
(2)只有当涉及到快照目录的修改被执行时,才会产生额外的内存消耗。而且内存消耗为O(M),其中M是被修改的文件或目录数。
(3)创建快照时,block块并不会被拷贝。快照文件中只记录了block列表和文件大小,不会做任何数据拷贝。
(4)快照不会对正常的HDFS操作有任何影响:创建快照以后发生的修改操作,被按操作时间的倒序(from newer to older)记录下来。所以当前的数据能被直接获取,而快照点的数据,则通过在当前的数据基础上减去执行过的操作来获取。
-
可以在任何被设置为snapshottable的目录上执行快照,对一个目录最多可以创建65536个快照。管理员可以把任何目录设置为snapshottable,没有限制。如果一个目录下已经存在快照,那么只有当先删除所有快照后才能对这个目录进行删除和重命名等操作。
-
快照被存放在一个被命名为.snapshot的目录中。如/foo是一个snapshottable目录,/foo中有一个目录为/foo/bar,对/foo创建一个快照s0。/foo/.snapshot/s0/bar,就是/foo/bar目录对应的快照。可以通过".snapshot"路径直接访问和操作快照数据。
-
快照操作
-
设置允许对一个目录创建快照: hdfs dfsadmin -allowSnapshot /user/spark
-
目录创建快照: hdfs dfs -createSnapshot /user/spark s0
-
重命名快照: hdfs dfs -renameSnapshot /user/spark s0 s_init
-
删除快照: hdfs dfs -deleteSnapshot /user/spark s_init
-
把原本snapshottable的目录设置为禁止快照: hdfs dfsadmin -disallowSnapshot /user/spark
-
列出一个目录的所有快照:hdfs dfs -ls /foo/.snapshot
-
列出快照s0中的所有文件:hdfs dfs -ls /foo/.snapshot/s0
-
从快照中复制文件:hdfs dfs -cp /foo/.snapshot/s0/bar /tmp
-
HDFS缓存
HDFS中的集中化缓存管理允许用户指定要缓存的HDFS路径。NameNode会和保存着所需blocks数据的所有DataNode通信,并指导他们把blocks数据缓存在off-heap缓存中。
-
HDFS集中化缓存管理的优势:
-
明确的锁定,可以阻止频繁使用的数据被从内存中清除。当工作集的大小超过了主内存大小时,这一点尤为重要。
-
由于DataNode缓存是由NameNode管理的,所以,在确定任务放置位置时,应用程序可以查询一组缓存块位置。把任务和缓存块副本放在一个位置上可以提高读操作的性能。
-
当blocks已经被DataNode缓存时,客户端就可以使用一个新的更高效的零拷贝读操作API。因为缓存数据的checksum校验只需由DataNode执行一次,所以,使用这种新API时,客户端基本上不会有开销。
-
集中缓存可以提高整个集群的内存使用率。当依赖于每个DataNode上操作系统的buffer缓存时,重复读取一个块数据会导致该块的N个副本全部被送入buffer缓存。使用集中化缓存管理,用户就能明确地只锁定这N个副本中的M个了,从而节省了N-M的内存量。
-
-
使用场景:
例如,Hive中的一个较小的fact表,常常用于joins操作就是一个很好的缓存对象。
-
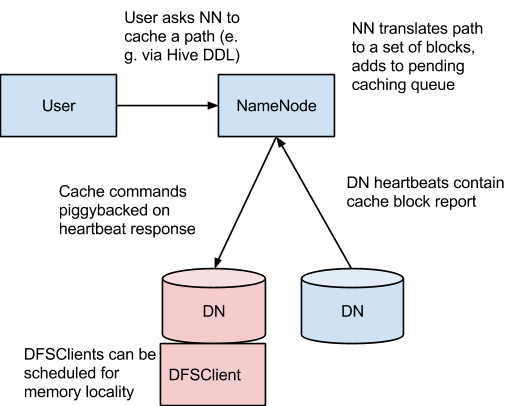
上图中,NameNode负责协调集群中所有DataNode的off-heap缓存。NameNode周期性地接收来自每个DataNode的缓存报告。NameNode通过借助DataNode心跳上的缓存和非缓存命令来管理DataNode缓存。
-
NameNode查询自身的缓存指令集来确定应该缓存那个路径。缓存指令永远存储在fsimage和edit日志中,而且可以通过Java和命令行API被添加、移除或修改。NameNode还存储了一组缓存池,它们是用于把资源管理类和强制权限类的缓存指令进行分组的管理实体。
-
NameNode周期性地扫描命名空间和活跃的缓存以确定需要缓存或不缓存哪个块,并向DataNode分配缓存任务。
-
集中化缓存管理对于重复访问的文件很有用。但是当前只实现了文件或目录级的缓存。块和子块缓存是未来的目标。
HDFS ACL
-
Hadoop从2.4.0开始支持
-
目前HDFS的权限控制与Linux一致,包括用户、用户组、其他用户组三类权限
-
首先参数上要开启基本权限和访问控制列表功能(默认情况下ACLs是关闭的,想要开启此功能需要在hdfs-site.xml的配置项里找到dfs.namenode.acls.enabled把属性设为true才可以。重要:Namenode节点必须要设定的用户或用户组)
dfs.permissions.enabled
dfs.namenode.acls.enabled
- 常用命令:
getfacl
用于查看一个文件/目录的ACL状态
hadoop fs -getfacl /input/acl
hdfs dfs -setfacl [-R] [-b|-k -m|-x <acl_spec> <path>]|[--set <acl_spec> <path>]
<!-- COMMAND OPTIONS
<path>: 路径
-R: 遍历路径里的所有文件。
-b: 撤销除了基本用户和组权限以外的所有权限。
-k: 撤销默认的ACL设置。
-m: 添加新的权限来使用此ACL。不影响现有权限。
-x: 只撤销指定的ACL。
<acl_spec>: 逗号分隔的ACL权限列表。
--set: 使用该选项指定的路径完全取代现有的ACL。
之前的ACL将不再适用。
-->
setfacl
设置user用户及mapred用户组对/input/acl读的权限
hdfs dfs -setfacl -m user:mapred:r-- /input/acl
关于权限标志位的顺序: 在命令hadoop dfs -setfacl -m user:mapred:rwx /user/xt-data中,权限标志位rwx的顺序不能改变,否则会报错:-setfacl: Invalid permission in 正确的写法有: rwx, r-x, -r-, -rx等;
撤销user用户及mapred用户组对/input/acl路径的ACL
hdfs dfs -setfacl -x user:mapred /input/acl
