问题概述
搜索相关信息有时感觉就像大海捞针,但不要绝望,GPT 实际上可以为我们做很多这样的工作。在本文中,我们探索了一种使用各种 AI 技术增强现有搜索系统的方法,帮助我们筛选有价值信息。
检索 GPT 信息的两种方法是:
- 模仿人类浏览(Mimicking Human Browsing):GPT 触发搜索,评估结果,并在必要时修改搜索查询。它还可以跟进特定的搜索结果以形成思维链,就像人类用户所做的那样。
- 使用嵌入进行检索(Retrieval with Embeddings):计算内容和用户查询的嵌入,然后检索最相关的内容(按余弦相似度衡量)。这种技术被谷歌等搜索引擎大量使用。
这些方法都很有前途,但都有其缺点:第一种方法由于其迭代性质而可能很慢,第二种方法需要提前嵌入整个知识库,不断嵌入新内容并维护矢量数据库。
通过结合这些方法,并从重新排名方法中汲取灵感,我们确定了一种介于两者之间的方法。这种方法可以在任何现有的搜索系统之上实现,例如 Slack 搜索 API,也可以在包含私有数据的内部 ElasticSearch 实例上实现。其工作原理如下:
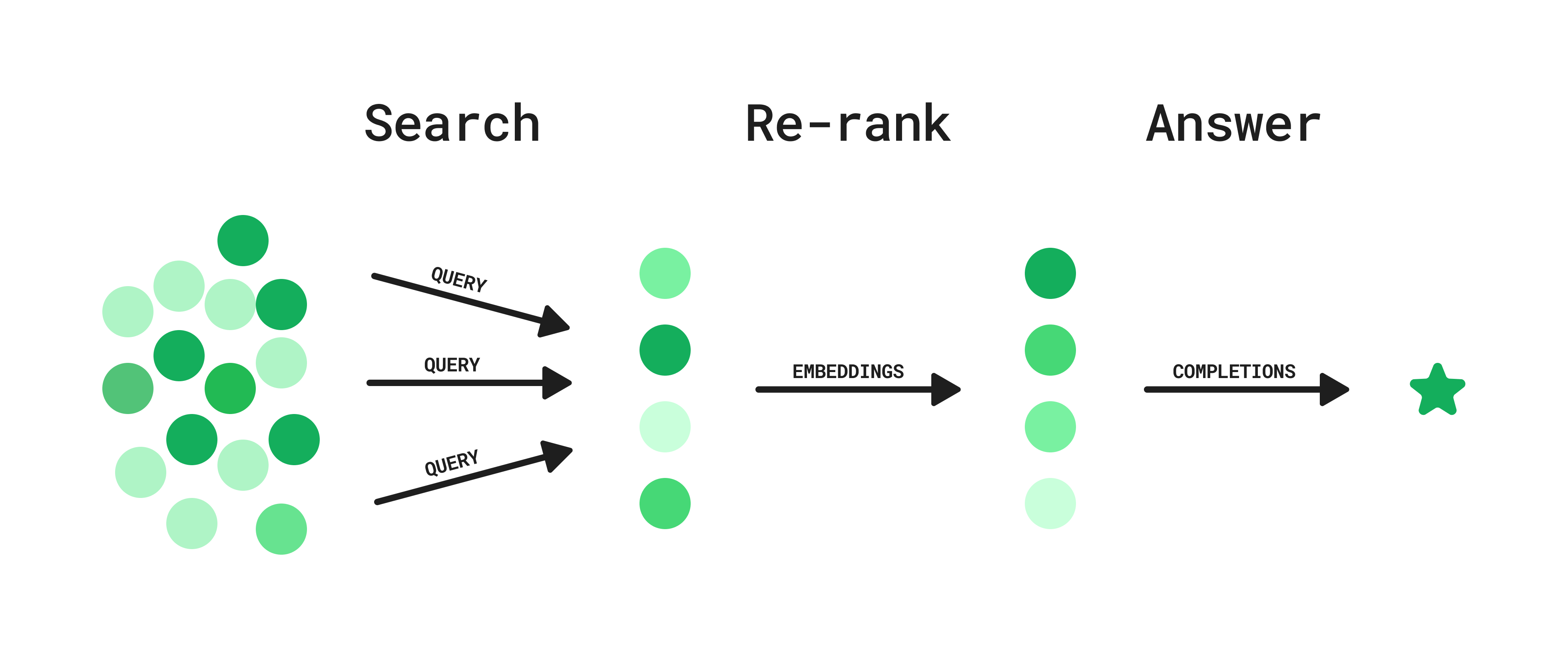
解决思路
第 1 步:搜索
- 用户提出问题。
- GPT 生成潜在查询列表。
- 搜索查询并行执行。
第 2 步:重新排名
- 每个结果的嵌入用于计算语义相似性,以生成用户问题的假设理想答案。
- 根据此相似性指标对结果进行排名和筛选。
第 3 步:回答
- 给定排名靠前的搜索结果,该模型会生成用户问题的答案,包括引用和链接。
这种混合方法提供相对较低的延迟,并且可以集成到任何现有的搜索 API 中,而无需维护向量数据库。下面我们将使用新闻 API 作为示例进行搜索。
代码实现
0.环境准备
设置 OPENAI_API_KEY、 NEWS_API_KEY 环境变量。
准备工具函数
# Dependencies
from datetime import date, timedelta # date handling for fetching recent news
from IPython import display # for pretty printing
import json # for parsing the JSON api responses and model outputs
from numpy import dot # for cosine similarity
from openai import OpenAI
import os # for loading environment variables
import requests # for making the API requests
from tqdm.notebook import tqdm # for printing progress bars
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "<your OpenAI API key if not set as env var>"))
# Load environment variables
news_api_key = os.getenv("NEWS_API_KEY")
GPT_MODEL = "gpt-3.5-turbo"
# Helper functions
def json_gpt(input: str):
completion = client.chat.completions.create(model=GPT_MODEL,
messages=[
{"role": "system", "content": "Output only valid JSON"},
{"role": "user", "content": input},
],
temperature=0.5)
text = completion.choices[0].message.content
parsed = json.loads(text)
return parsed
def embeddings(input: list[str]) -> list[list[str]]:
response = client.embeddings.create(model="text-embedding-3-small", input=input)
return [data.embedding for data in response.data]
1. 搜索
用户提出问题
# User asks a question
USER_QUESTION = "Who won the NBA championship? And who was the MVP? Tell me a bit about the last game."
现在,为了尽可能详尽,使用该模型根据此问题生成各种查询的列表。
QUERIES_INPUT = f"""
You have access to a search API that returns recent news articles.
Generate an array of search queries that are relevant to this question.
Use a variation of related keywords for the queries, trying to be as general as possible.
Include as many queries as you can think of, including and excluding terms.
For example, include queries like ['keyword_1 keyword_2', 'keyword_1', 'keyword_2'].
Be creative. The more queries you include, the more likely you are to find relevant results.
User question: {USER_QUESTION}
Format: queries
"""
queries = json_gpt(QUERIES_INPUT)["queries"]
# Let's include the original question as well for good measure
queries.append(USER_QUESTION)
queries
输出如下:
['NBA championship winner',
'MVP of NBA championship',
'Last game of NBA championship',
'NBA finals winner',
'Most valuable player of NBA championship',
'Finals game of NBA',
'Who won the NBA finals',
'NBA championship game summary',
'NBA finals MVP',
'Champion of NBA playoffs',
'NBA finals last game highlights',
'NBA championship series result',
'NBA finals game score',
'NBA finals game recap',
'NBA champion team and player',
'NBA finals statistics',
'NBA championship final score',
'NBA finals best player',
'NBA playoffs champion and MVP',
'NBA finals game analysis',
'Who won the NBA championship? And who was the MVP? Tell me a bit about the last game.']
查询生成查询效果,接下来使用这些问题运行搜索。
def search_news(
query: str,
news_api_key: str = news_api_key,
num_articles: int = 50,
from_datetime: str = "2023-06-01", # the 2023 NBA finals were played in June 2023
to_datetime: str = "2023-06-30",
) -> dict:
response = requests.get(
"https://newsapi.org/v2/everything",
params={
"q": query,
"apiKey": news_api_key,
"pageSize": num_articles,
"sortBy": "relevancy",
"from": from_datetime,
"to": to_datetime,
},
)
return response.json()
articles = []
for query in tqdm(queries):
result = search_news(query)
if result["status"] == "ok":
articles = articles + result["articles"]
else:
raise Exception(result["message"])
# remove duplicates
articles = list({article["url"]: article for article in articles}.values())
print("Total number of articles:", len(articles))
print("Top 5 articles of query 1:", "\n")
for article in articles[0:5]:
print("Title:", article["title"])
print("Description:", article["description"])
print("Content:", article["content"][0:100] + "...")
print()
输出如下:
Total number of articles: 554
Top 5 articles of query 1:
Title: Nascar takes on Le Mans as LeBron James gets centenary race under way
Description: <ul><li>Nascar has presence at iconic race for first time since 1976</li><li>NBA superstar LeBron James waves flag as honorary starter</li></ul>The crowd chanted “U-S-A! U-S-A!” as Nascar driver lineup for the 24 Hours of Le Mans passed through the city cente…
Content: The crowd chanted U-S-A! U-S-A! as Nascar driver lineup for the 24 Hours of Le Mans passed through t...
Title: NBA finals predictions: Nuggets or Heat? Our writers share their picks
Description: Denver or Miami? Our contributors pick the winner, key players and dark horses before the NBA’s grand finale tips offA lot has been made of the importance of a balanced roster with continuity, but, somehow, still not enough. The Nuggets are the prime example …
Content: The Nuggets are here because
A lot has been made of the importance of a balanced roster with conti...
正如我们所看到的,搜索查询通常会返回大量结果,其中许多结果与用户提出的原始问题无关。为了提高最终答案的质量,我们使用嵌入来重新排名和过滤结果。
2.重新排名
从 HyDE(Gao等人)中汲取灵感,首先生成一个假设的理想答案,以重新排序上面的结果。下面是我们用来生成假设答案的提示。
HA_INPUT = f"""
Generate a hypothetical answer to the user's question. This answer will be used to rank search results.
Pretend you have all the information you need to answer, but don't use any actual facts. Instead, use placeholders
like NAME did something, or NAME said something at PLACE.
User question: {USER_QUESTION}
Format: hypotheticalAnswer
"""
hypothetical_answer = json_gpt(HA_INPUT)["hypotheticalAnswer"]
hypothetical_answer
输出如下:
'The NBA championship was won by TEAM NAME. The MVP was awarded to PLAYER NAME. The last game was held at STADIUM NAME, where both teams played with great energy and enthusiasm. It was a close game, but in the end, TEAM NAME emerged victorious.'
现在,让我们为搜索结果和假设答案进行 embeddings。然后,我们计算这些 embeddings 之间的余弦距离,从而给出语义相似度指标。请注意,我们可以简单地计算点积,而不是进行完整的余弦相似度计算,因为 OpenAI 嵌入在我们的 API 中是归一化的。
hypothetical_answer_embedding = embeddings(hypothetical_answer)[0]
article_embeddings = embeddings(
[
f"{article['title']} {article['description']} {article['content'][0:100]}"
for article in articles
]
)
# Calculate cosine similarity
cosine_similarities = []
for article_embedding in article_embeddings:
cosine_similarities.append(dot(hypothetical_answer_embedding, article_embedding))
cosine_similarities[0:10]
输出结果如下:
[0.7854456526852069,
0.8086023500072106,
0.8002998147018501,
0.7961229569526956,
0.798354506673743,
0.758216458795653,
0.7753754083127359,
0.7494958338411927,
0.804733946801739,
0.8405965885235218]
最后,我们使用这些相似性分数对结果进行排序和过滤。
scored_articles = zip(articles, cosine_similarities)
# Sort articles by cosine similarity
sorted_articles = sorted(scored_articles, key=lambda x: x[1], reverse=True)
# Print top 5 articles
print("Top 5 articles:", "\n")
for article, score in sorted_articles[0:5]:
print("Title:", article["title"])
print("Description:", article["description"])
print("Content:", article["content"][0:100] + "...")
print("Score:", score)
print()
输出结果
Title: NBA Finals: Denver Nuggets beat Miami Hea, lift thier first-ever NBA title
Description: Denver Nuggets won their maiden NBA Championship trophy defeating Miami Heat 94-89 in Game 5 of the NBA Final held on Tuesday at the Ball Arena in Denver
Content: Denver Nuggets won their maiden NBA Championship trophy defeating Miami Heat 94-89 in Game 5 of the ...
Score: 0.8445817523602124
Title: Photos: Denver Nuggets celebrate their first NBA title
Description: The Nuggets capped off an impressive postseason by beating the Miami Heat in the NBA Finals.
Content: Thousands of supporters watched along the streets of Denver, Colorado as the US National Basketball ...
Score: 0.842070667753606
Title: Denver Nuggets win first NBA championship title in Game 5 victory over Miami Heat
Description: The Denver Nuggets won their first NBA championship Monday night, downing the Miami Heat 94-89 at Ball Arena in Denver to take Game 5 of the NBA Finals.
Content: The Denver Nuggets won their first NBA championship Monday night, downing the Miami Heat 94-89 at Ba...
Score: 0.8409346078172385
棒!这些结果看起来与我们的原始查询更相关。现在,让我们使用前 5 个结果来生成最终答案。
3.回答
formatted_top_results = [
{
"title": article["title"],
"description": article["description"],
"url": article["url"],
}
for article, _score in sorted_articles[0:5]
]
ANSWER_INPUT = f"""
Generate an answer to the user's question based on the given search results.
TOP_RESULTS: {formatted_top_results}
USER_QUESTION: {USER_QUESTION}
Include as much information as possible in the answer. Reference the relevant search result urls as markdown links.
"""
completion = client.chat.completions.create(
model=GPT_MODEL,
messages=[{"role": "user", "content": ANSWER_INPUT}],
temperature=0.5,
stream=True,
)
text = ""
for chunk in completion:
text += chunk.choices[0].delta.content
display.clear_output(wait=True)
display.display(display.Markdown(text))
推荐阅读
- LLMs:Embeddings-based 的搜索进行问答
- TaskWeaver + Planner + 插件 = 超级 AI Agent
- 这个 Prompt,为我节省了不少钱
- 将 ChatGPT 与实时数据结合原理分析(附代码分析)
参考资料:
Question answering using a search API and re-ranking | OpenAI Cookbook
欢迎关注公众号,更及时的接收消息,后续会继续写一些相关 ChatGPT 的文章。
